Data Flow
This article provides a detailed description of the interaction between the IOTA 2.0 protocol components. You can divide the protocol into three main elements:
- A P2P overlay network.
- An immutable data structure.
- A consensus mechanism.
In the IOTA 2.0 protocol, these three elements are abstracted into layers, where upper layers build on the functionality of the layers below. The definition of these layers allows for different functionalities to be conveniently separated into modules and addressed individually. This article will describe all the modules and their interactions.
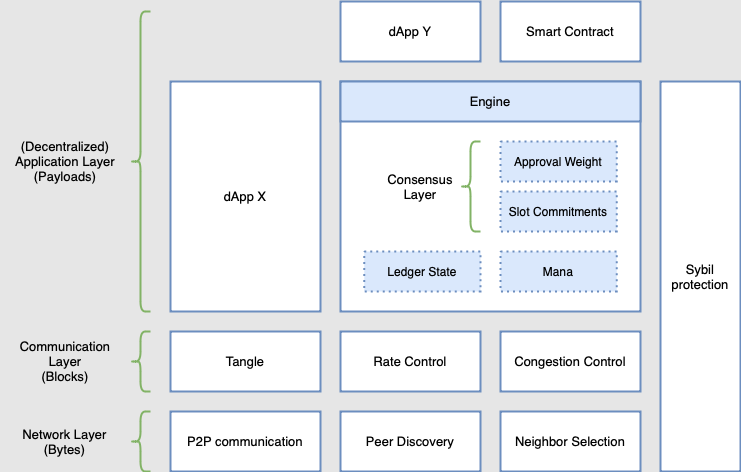
Image 1: Different layers of the protocol.
1. Network Layer
The network will be maintained by the network layerThe layer of the IOTA protocol responsible for managing the P2P overlay network, including peer discovery, neighbor selection, and gossip. modules, which can be characterized as a pure P2P overlay network. This means that it is a system that runs on top of another network (e.g., the internet), but unlike client-server systems, all nodes have the same roles and perform the same actions.
IOTA 2.0's Network Layer consists of two primary modules: the peer discoveryModule in the Network Layer that looks for nodes that participate in the network. module, which maintains a list of nodes actively using the network, and the neighbor selection module (also known as autopeeringA mechanism enabling nodes to select their neighbors automatically, without the node operator's manual intervention. module), which selects peers in a random secure way. The network layer also manages the gossip between nodes.
2. Communication Layer
The communication layer's concern is the information propagated through the network layer, contained in objects called blocks. This layer builds a DAG with blocks as vertices called The Tangle: a replicated, shared, and distributed data structureA data structure is a way of organizing data so that it can be efficiently and effectively used. The Tangle uses a variety of data structures, including blocks, payloads, transactions, and commitments, to store and process data. that emerges through a combination of deterministic rules, cooperation, and direct or virtual voting.
Since nodes have finite capabilities, the network can process a limited number of blocks. Thus, the network could become overloaded simply because of honest heavy usage or malicious (spam) attacks. To protect the network from coming to a halt or just getting inconsistent, the rate control and congestion control modules control when and how many blocks can be gossiped.
3. (Decentralized) Application Layer
The application layerHandles block contents and payloads, especially significant for consensus and ledger state maintenance. All applications use the communication layer to transmit and store data. lives on top of the communication layerManages how blocks connect with each other to form the Tangle, regulated by the Rate Control and Congestion Control.. The application layerHandles block contents and payloads, especially significant for consensus and ledger state maintenance. All applications use the communication layer to transmit and store data. is mainly related to objects called payloads (e.g., transactions are a type of payload). Anybody can develop applications on this layer, and nodes can choose which applications to run. Of course, these applications can also be dependent on each other.
Nodes must also run several core applications, such as the engine, which maintains the ledger state and a quantity called Mana. Mana is a scarce resource that serves as a Sybil protection mechanismA mechanism that prevents malicious users from overwhelming the network by creating multiple fake identities (Sybil attacks). and spam protection. All nodes must also run the Approval Weight and Finality Gadget application, which provides a protocol that produces consensus between nodes on whether blocks are to be included in the Tangle (instead of being orphaned) and on whether transactions inside included blocks should mutate the ledger (instead of being deemed non-mutating). Lastly, the same gadget enables nodes to reorganize their perception of the Tangle when necessary, using the fork-choice ruleAn algorithm for choosing between several chains; IOTA 2.0"s solution is the Chain-Switching Rule..
4. Data Flow
Overview
The diagram below represents the interaction between the different modules in the protocol. Each blue box represents a component with events that belong to it, represented by yellow boxes. Those events will trigger methods (the green boxes) that can also trigger other methods. This triggering is represented by the arrows in the diagram. Finally, the purple boxes represent events not belonging to the component that triggered them.
For example, take the ParserInitial step of the Data Flow, translates bytes into usable information, filtering out redundant or invalid data. component. The function ProcessGossipBlock will trigger the method Parse, the only component entry. There are three possible outcomes to the Parser:
- Triggering a
ParsingFailedevent. - Triggering a
BlockFilteredevent. - Triggering a
BlockParsedevent.
In the last case, the event will trigger the Attach method (the entry to the Block DAG component), whereas the first two events do not trigger any other component.
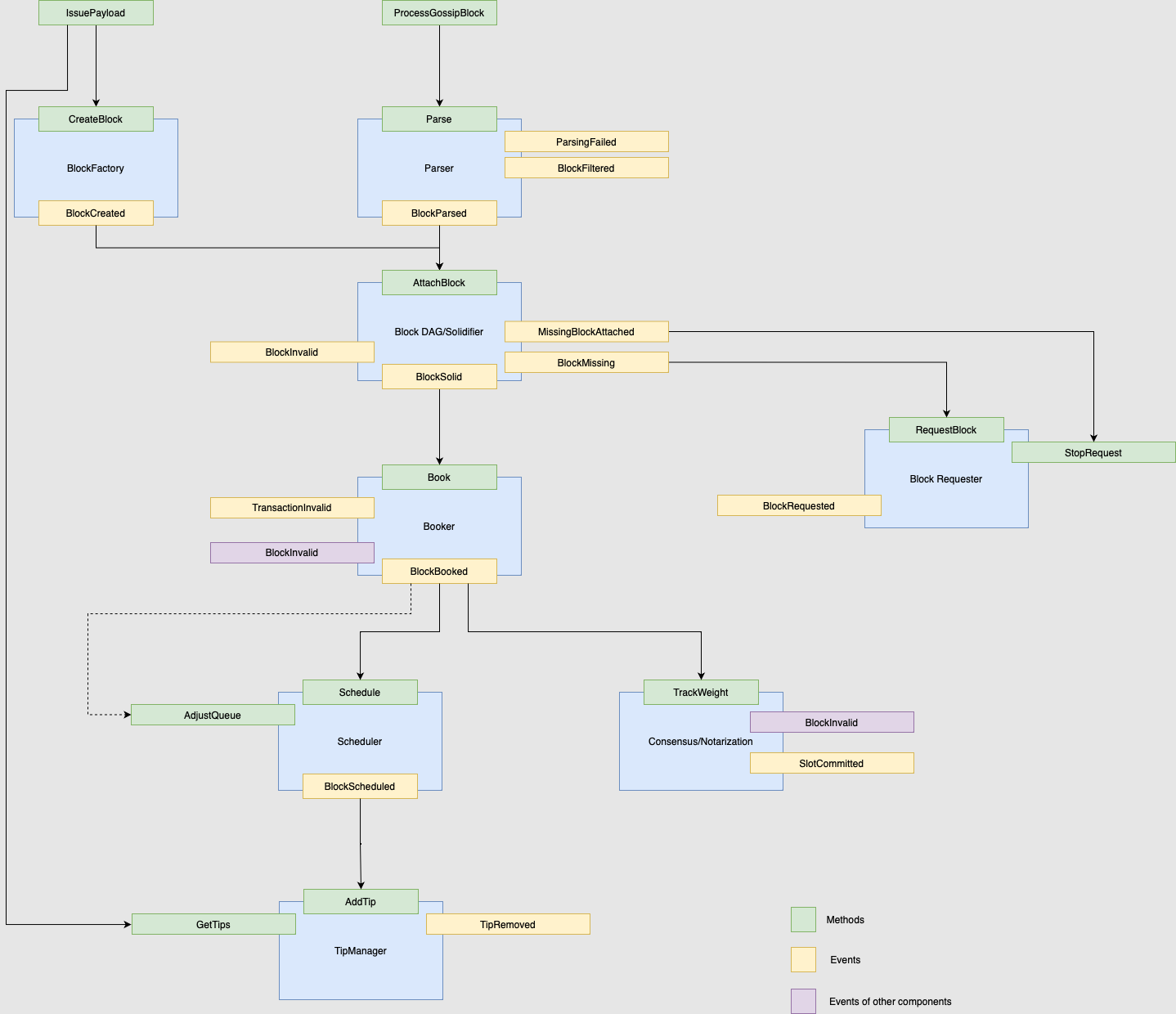
Image 2: Data flow overview.
We present the data flow, i.e., the life cycle of a block, from block receptionThe process of receiving blocks, either created locally by a node or received from a neighbor. (or creation) until acceptance in the Tangle. Notice that any block created locally by the node or received from a neighbor must pass through most of the data flow. Specifically, all blocks pass from the Block DAG component to the Tip ManagerAdds scheduled blocks to tip pool, maintains tip pool by removing too old or newly approved blocks. and the consensus/Notarization. The Data Flow (Image 2) is almost precise; however, some of the components' explanations were simplified for didactic purposes. Please see the node software documentation for a precise representation of each component's implementation.
Finally, note that this Data Flow concerns nodesA node is any computer that communicates with other nodes in the network using specific software. Essentially, nodes act as connection points for data transfers. The Tangle employs various node types, including full nodes (Hornet, Bee), permanodes (Chronicle), and smart contract nodes (Wasp). and not clients. Clients generally do not contribute to consensus and just contain a Block Factory.
4.1 Block Factory
The IssuePayload function creates a valid payload, provided to the CreateBlock method, along with a set of parents chosen with the Tip Selection Algorithm. Then, the block is signed. Notice that block generation should follow the rates imposed by the rate setterA module that determines the fair rate at which an issuer can issue new blocks., as defined in r rate control, and that the block's type of references should be consistent with the preferred reality of the issuer(see the consensus article.
All blocks have a commitment fieldA field in a block that contains a hash of information from older slots and is used for creating Slot Commitment Chains., which is the hash of a series of information from older slots (see Data Structures), e.g., the Merkle root of the Merkle Tree containing the blocks included in the older slots, ledger state at the end of the slots, or Block Issuance Credits.
There are certain rules for creating the commitment: A block must not commit to excessively old slots, for example, the "genesis" slot. A block must not commit to excessively recent slots. For example, the slot to which the block belongs, since the information the block commits to might still change.
By comparing these commitments, it becomes straightforward to identify the existence of divergences between the nodes' perceptions of the Tangle. Additionally, these commitments in the blocks enable the creation of _Slot Commitment Chain_s (see Data Structures and the Finality Gadget).
4.2 Parser
After the block arrives in the block inboxThe initial destination for incoming blocks that need to be parsed and processed. , the next step is parsing, where the received bytes are interpreted and translated into information that can be processed by nodes (a block, possibly containing a payload, with parents, timestamps, etc.). The parsing consists of the seven following filtering processes. Blocks that don't pass any of these steps will not continue the data flow:
4.2.1 Recently seen bytes
This process compares the incoming blocks with a pool of recently seen bytes to filter duplicates. If the block does not pass this check, the block is dropped. If it passes the check, it goes to the next step.
4.2.2 Parsing and syntactical validation
This process checks if the block and the payload (when present) are syntactically valid. In particular, this validation checks block length, number of parents, and the existence of trailing bytes left unparsed.
If the parsing fails, a ParsingFailed event is triggered; if the Syntactical Validation fails, a BlockFiltered event is triggered. If it passes both checks, it goes to the next step.
4.2.3 Timestamp difference check
This process checks if the creation time of the payload and the block timestamps are consistent, i.e., if transaction.creationtTime <= block.issuingTime. This step is only executed when the block contains a payload.
If the block does not pass this check, a BlockFiltered event is triggered. If it passes the check, it goes to the next step. Additionally, a block will not pass this check if its timestamp is too far in the future.
4.2.5 Mana check
This process checks if the RMC (Reference Mana Cost) requirements are met, as defined in Congestion Control. To summarize, this step checks if the Mana burnt in the block is larger or equal to the Reference Mana Cost of the slot times the block's workscore. Both the RMC and workscore calculations are objective, so if a block does not burn the required Mana, it can be directly rejected.
It also checks if the account BIC committed at maxCommitableAge slots in the past is non-negative, among other account-related filters.
If the block does not pass this check, a BlockFiltered event is triggered. If it passes the check, it goes to the next step.
4.2.6 Slot commitment check
This process checks if the slot the block commits to is neither too old nor too recent. If the block does not pass this check, a BlockFiltered event is triggered. If it passes the check, it goes to the next step.
4.2.7 Signature check
This process checks if the block signatureDigital signatures attached to blocks to ensure their authenticity. is valid. If the block does not pass this check, a BlockFiltered event is triggered. If it passes the check, a BlockParsed event is issued, which will trigger the Block DAG module.
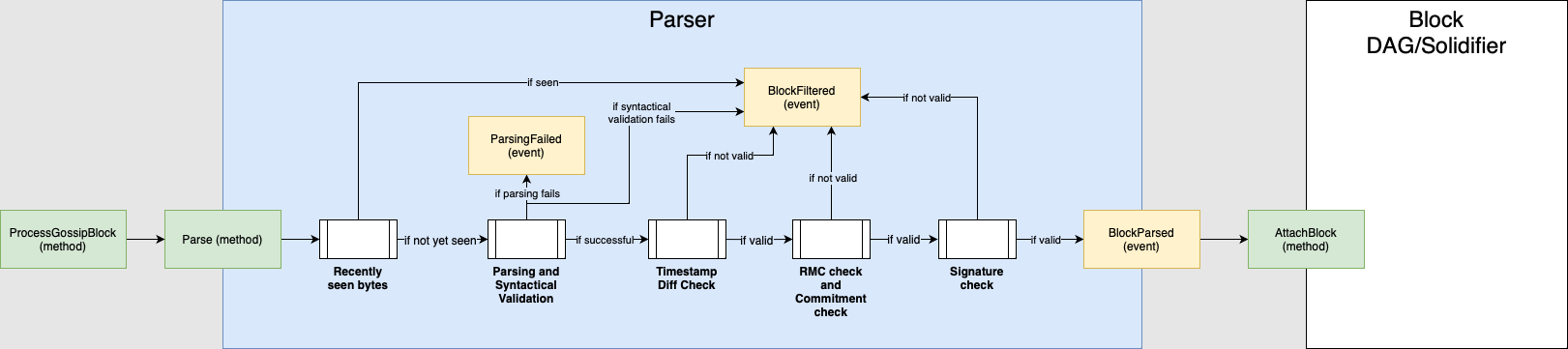
Image 3: The parser.
4.3 Block DAG/Solidifier
Only the blocks that pass the Parser are stored in memory with some metadata as boolean flags set in future points of the data flow. This process takes place in the Block DAG component, where blocks are causally ordered and their dependencies are defined.
SolidificationThe process of ensuring that a block has all its dependencies and can be considered solid within the Tangle. also takes place in the Block DAG. Solidification is the process of requesting missing blocks. In this step, the node checks if all the past coneThe set of messages that are directly or indirectly referenced by a given message is termed its past cone. (see consensus) of the block is known. If the node realizes that a block in the past cone is missing, it will send a request to its neighborsDirectly connected network nodes that can exchange messages without intermediary nodes. asking for that missing block. This process is recursively repeated until all of a block's past cone up to the genesis (or snapshot) becomes known to the node.
This way, the protocol enables any node to retrieve the entire block history (or at least until the last available snapshot) by processing the newly received blocks, even for nodes that have just joined the network.
When the solidification process of a block ends successfully, the protocol sets the solid flag in its metadata to TRUE.
If the process does not terminate successfully, the protocol will set the invalid flag to TRUE.
If, while solidifying, the node realizes that one of the parents of the block is invalid, the block itself is also marked as invalid.
The solidifierEnsures blocks are consistently linked to past blocks, creating solidity and preventing missing information when tracing back in time. will also perform the parents' age check. It consists of checking if the timestamp of the block and the timestamps of each of its parents are monotonic: block.issuingTime >= parent.issuingTime.
This condition is necessary to guarantee the monotonicity of the Tangle, i.e., that the timestamps of the blocks increase with respect to the direction in which the Tangle is growing. As in the solidification case, the block is marked as invalid if the above condition is not met. If the block passes all the checks above, a BlockSolid event is issued, which will trigger the Booker module.
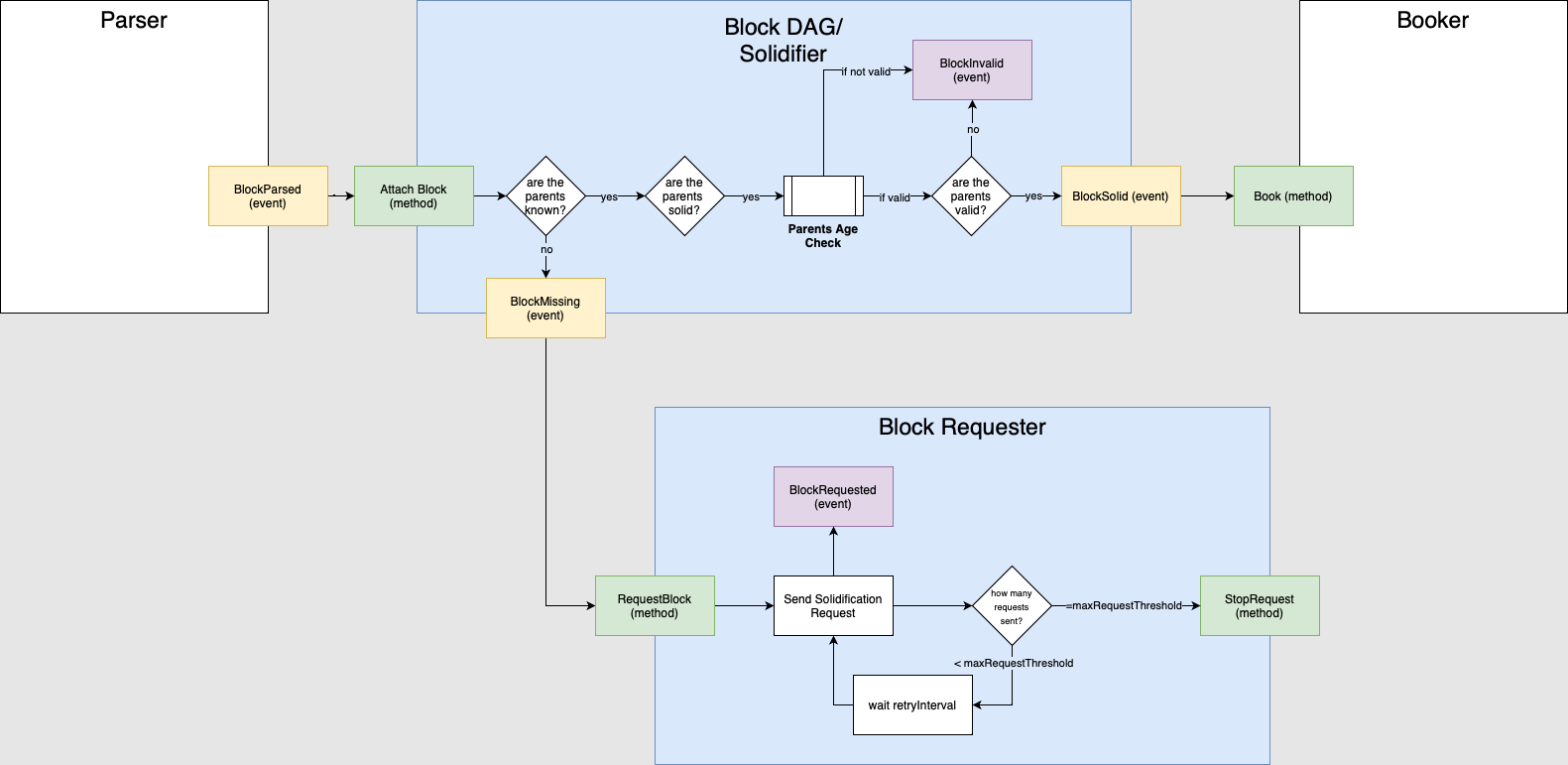
Image 4: The Block DAG/Solidifier component.
4.4 Booker
After solidification, the block moves on to the bookerResponsible for Tangle and ledger order, managing received blocks, and identifying conflicts. Creates conflicts in the ledger., where transactions are causally ordered, conflicts are identified, and the ledger state is updated.
Booking a transaction does not mean confirming a transaction. Our protocol optimistically books transactions even when they conflict, tracks these conflicts and their dependencies accordingly, and creates a collection of different realities (see Reality-based UTXO ledger) that are collapsed into a single confirmed reality at the end of the consensus process.
The booking step is different between blocks that contain a transaction payload and blocks that do not contain it. In the case of a block without a transaction payload, booking into the Tangle occurs after the block has waited in a buffer until all its parents are booked. In the booking process, all conflicts are inherited from the parents, and a BlockBooked event is issued. This step allows the opinion of the block to be constructed. If any of the parents are marked as invalid, the block is also marked as invalid and a BlockInvalid event is issued.
In the case of a block with a transaction payload, the transaction must be booked before the block can be booked. As in the case of blocks, booking only happens after the transaction has waited in a buffer for all its inputs to be booked. If any of the inputs are marked as invalid, the transaction is also marked as invalid, and a TransactionInvalid event is issued. Otherwise, the transaction is sent to the VM, where it will be executed. If the execution is successful, the data flow continues (meaning that the transaction is booked and the component will now try to book the block); if the execution fails, a TransactionInvalid event is issued and the block is not booked.
When the transaction is executed, the booking process in the ledger checks if any of the consumed inputs have more than one spender. If they do, a new conflict is created and added to a ConflictSet, which contains all the spenders of the output, out of which only 1 can be accepted.
The VM will only execute the transaction if it passes objective checks, particularly the following:
Balances check
This process checks if the values of the generated outputs respect the transaction validation rules. Particularly, it checks if the sum of the IOTA values of the generated outputs equals the sum of the IOTA values of the consumed inputs (analogously, checks are done for any other native tokens).
It also checks if the Mana values of the generated outputs follow the Mana validation rules (see Data structures). If the transaction does not pass this check, it is marked as invalid and not executed. If it passes the check, it goes to the next step.
Unlock conditions
This process checks that the unlock conditions of the transaction are valid. If the transaction(see Data structures) fails to pass this check, it is marked as invalid and not executed. If it passes the check, it goes to the next step.
Inputs' validity check
This process checks that all the consumed inputs are not conflicting. If the transaction fails to pass this check, it is marked as invalid and not executed.
Finally, whenever a block is booked, it triggers the SchedulerA component that manages the scheduling of blocks for gossiping, ensuring fairness and preventing spam. and the consensus components (which work in parallel).
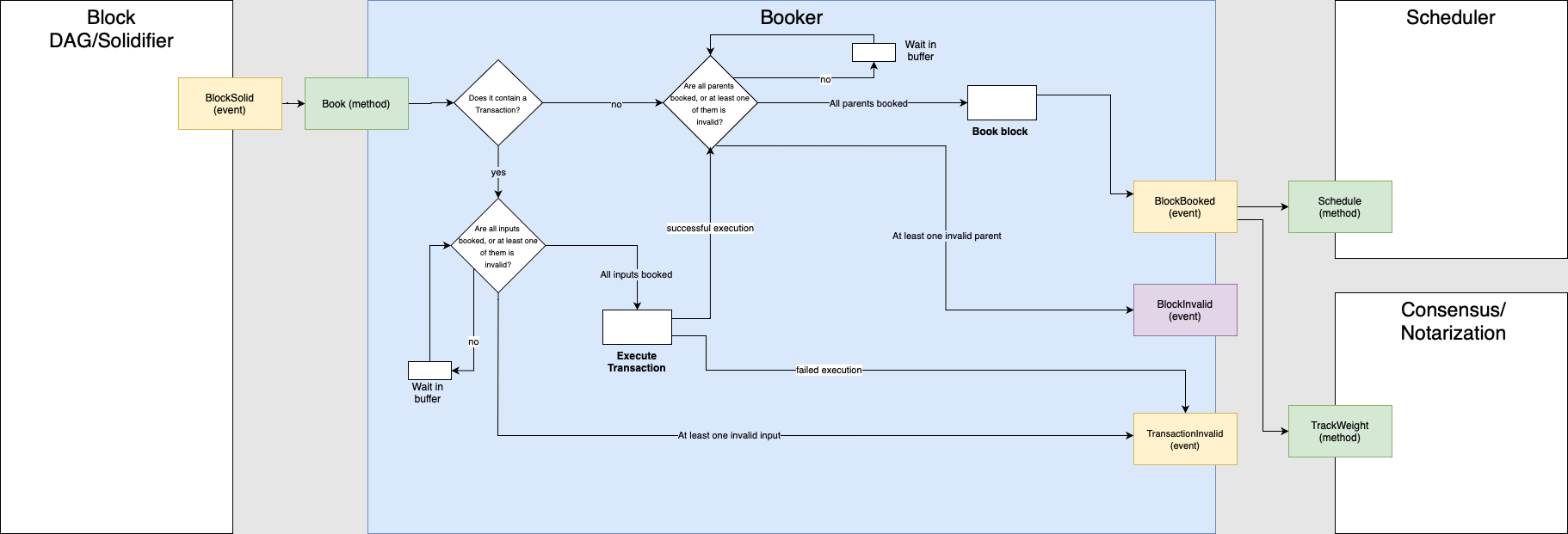
Image 5: The booker.
4.5 Scheduler
You can think of the scheduler as a gatekeeper that offers protection for your neighbors, since the protocol only gossips blocks that it has scheduled.
Once the steps above are successful, the block is enqueued into the outboxA buffer where soon-to-be-scheduled blocks are enqueued before they are gossiped to the network.. The outbox is split into several queues, each corresponding to a different block issuer. Those separate queues ensure that the minimum share of throughputThe rate or capacity at which transactions or data can be processed or transmitted within a given timeframe by the network. reserved to a certain block issuer is not affected by the network usage of the other nodes. Furthermore, separating blocks into different queues guarantees that no block issuersEntities responsible for creating and issuing new blocks into the network. will have their blocks delayed because of spamming from other issuers (see the Scheduler description in the Communication Layer wiki page).
Once the block is enqueued into the right queue, this queue is sorted by block timestamp in increasing order. This ensures that blocks are scheduled in the same order by every node with high probability. Furthermore, blocks can only be scheduled when ready, meaning that all parents are scheduled or accepted.
The dequeuing process (i.e., fetching the blocks from these queues to be gossiped and added to the tip pool) uses a modified version of the deficit round robin (DRR) algorithm, as described in Congestion Control. A maximum (fixed) global SCHEDULING_RATE, at which blocks will be scheduled, is set.
In severe congestion, when the buffer length exceeds a maximum length parameter, blocks will be dropped from the issuer queue's tail (latest timestamp). This buffer management policy favors the highest Mana nodes during periods of severe congestion, dropping blocks from low-Mana issuers first.
Blocks that are scheduled by the node can be gossiped and added to the tip pool.
4.6 Tip Manager
A scheduled block is finally added to one of two tip sets, "strong" and "weak" (for more details on the Tip Selection and Tip Pools, see Tip selection. Additionally, all strong parents of the scheduled block that are still part of the strong tip set are removed from it, whereas any parent in the weak tip is removed regardless of the reference type.
The tip selection mechanism performs a uniform random tip selection from a subset of the tip pool to guarantee good properties of the Tangle. Specifically, it will select tips uniformly at random only from tips that are not excessively old and pass the fishing condition. For that reason, when a block is to be issued and its parents are selected, the tip managerAdds scheduled blocks to tip pool, maintains tip pool by removing too old or newly approved blocks. will check if the selected parents respect these conditions and discard them if needed. In that case, the discarded parent is also removed from the tip set and a new parent is selected until the required number of parents is met.
After selecting parents, the algorithm chooses the type of reference (strong, weak, etc.) it uses for each parent, depending on the opinion the node has about the past cones of these parents (see consensus article).
Finally, if the block being issued is a validation block, the tip selection may differ from the tip selection of regular blocks; specifically, committee members will always try to reference all known blocks from other committee members (in addition to the random tips). For more details on the validation block tip selection, see the consensus article.
4.7 Consensus and Notarization
Booked blocks continue to the consensus and notarization component. In this component, the newly booked blocks will propagate the Witness Weight and Approval Weight from validation blocks to the blocks in their past cone and transactions they approve (see consensus article).
This propagation is independent: blocks always propagate Witness WeightMeasure of approval of each block using the voting power of the validation blocks" issuer. but not necessarily Approval WeightMeasure of approval of each conflicting transaction using the voting power of the validation blocks "issuer"., which depends on the type of reference that the block uses.
When blocks and transactions reach a certain Witness and Approval WeightMeasure of approval of each conflicting transaction using the voting power of the validation blocks "issuer". threshold, they are marked as accepted and confirmed (among other flags). Finally, these flags trigger the Notarization process, creating slot commitments.